

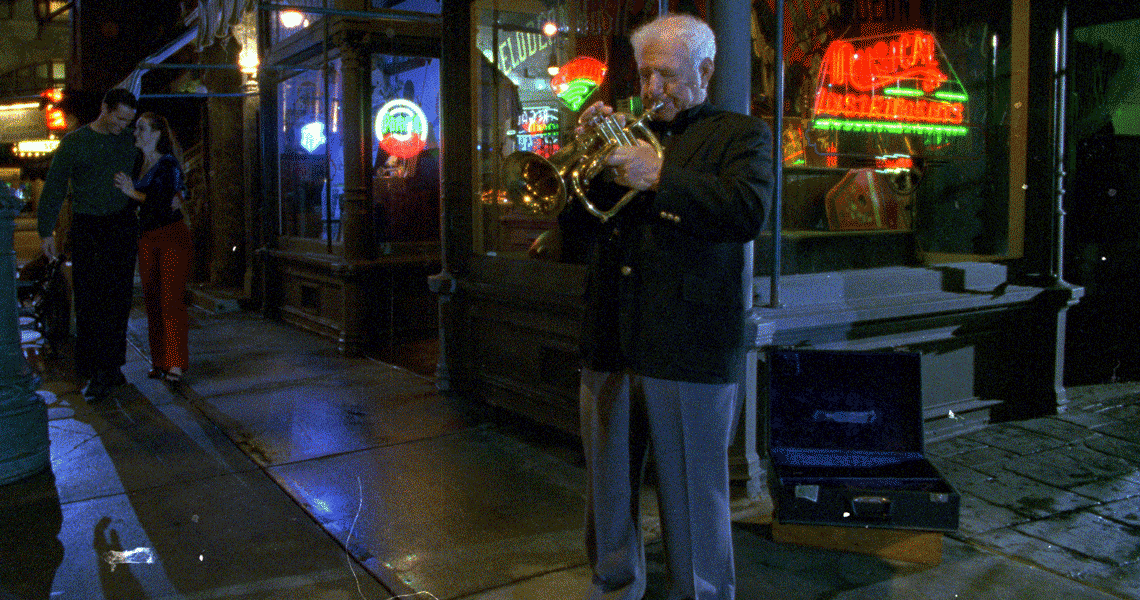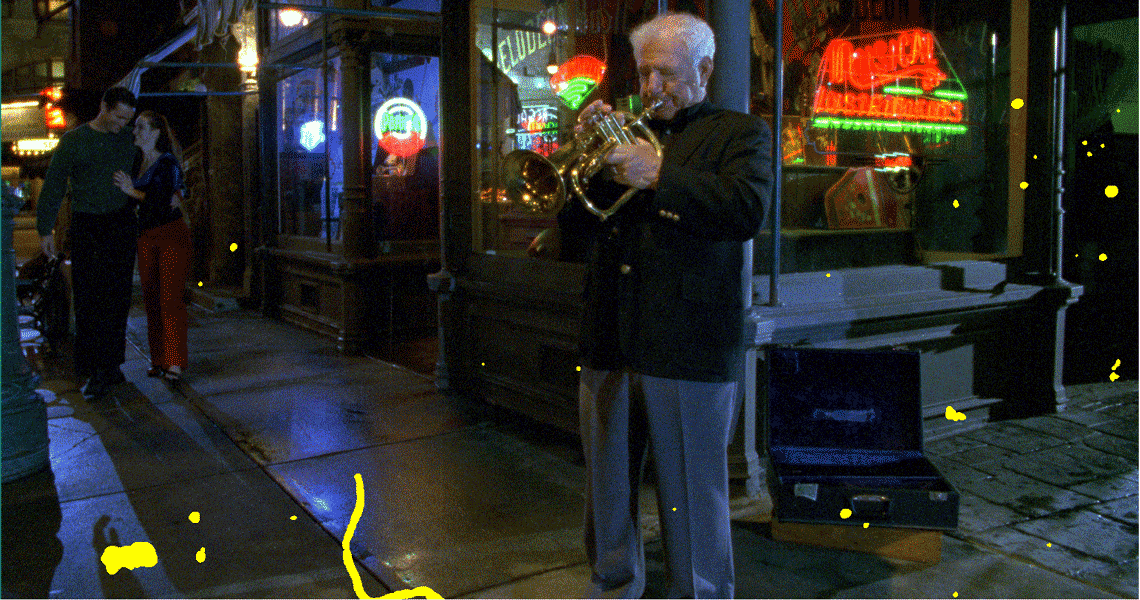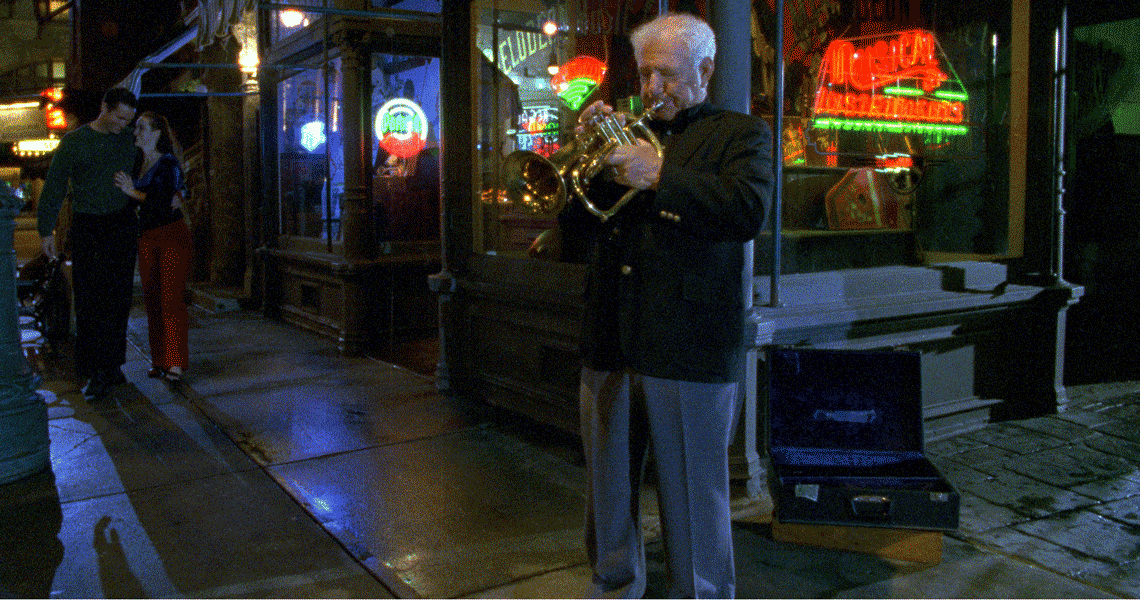

Defect.AI hat grundlegende Technologien für das dateneffiziente Training visueller Fehlererkennungsmethoden erforscht. Dabei kommen aktuelle Fortschritte im maschinellen Lernen zum Einsatz, wie beispielsweise Foundation-Modelle, die selbstüberwacht und mittels großer, nicht annotierter Datensätze trainiert und anschließend mittels Transferlernen an eine bestimmte Aufgabe angepasst werden. Die Arbeit bestätigt die Eignung von Foundation-Modellen (wie SWIN oder anderen Vision-Transformern) für Fehlererkennungsaufgaben, insbesondere bei kleinen Datensätzen. Ein wichtiger Aspekt in Anwendungsfällen im Medienbereich ist die Fähigkeit zur Erkennung anhand mehrerer Bilder. Die Robustheit der Fehlererkennung lässt sich massiv steigern, indem während des Trainings und des Inferenzprozesses mehrere aufeinanderfolgende Bilder eines Films oder Videos verwendet werden. Durch diesen Ansatz können zeitliche Eigenschaften von Fehlern vom Modell direkt berücksichtigt werden.
Die folgenden Bilder zeigen ein Beispiel für Einzelbildfehler, die durch Staub und Schmutz auf dem Film verursacht wurden (Originalbild links), wobei die Fehlererkennung (der erkannte Fehlerbereich ist in der Mitte dargestellt) der erste und entscheidende Schritt für die anschließende digitale Filmrestaurierung ist (das restaurierte Bild ist rechts dargestellt).

Ein weiterer wichtiger Aspekt ist die Erfassung des Expertenwissens, das in bestehenden, manuell entwickelten Detektoren steckt. Mithilfe von Wissensextraktion wird dieses spezifische Wissen in großem Maßstab und ohne manuelle Annotation erlernt. Dieses in einem Erkennungsmodell erfasste historische Wissen kann dann mit von Expert*innen annotiertem, hochwertigem Wissen verfeinert werden, wobei nur eine sehr geringe Anzahl von Experten-annotierten Beispielen erforderlich ist.
Wenn man nur wenige Beispiele zur Verfügung hat, ist es wichtig, dass man die Fähigkeit hat, Fehlerbeispiele in hoher Qualität zu ergänzen. Zu diesem Zweck haben wir Methoden erforscht, um Fehlerbeispiele aus einem Originalbild in eine Zwischenrepräsentation des Fehlers zu extrahieren und daraus eine große Anzahl von Fehlerbeispielen auf Zielbildern mit verschiedenen relevanten Inhaltseigenschaften (wie unterschiedliche Bewegungen, Helligkeiten…) und verschiedenen anderen Fehlereigenschaften (z. B. unterschiedliches Filmkornrauschen) zu generieren, wobei gleichzeitig das ursprüngliche Erscheinungsbild des Fehlers erhalten bleibt. Die folgenden Bilder zeigen das Originalbild mit einem enthaltenen Defekt, den extrahierten Defektbeispielbereich, den hochqualitativ generierten Ziel-Defektbereich und das gesamte Zielbild, das den generierten Defekt enthält. Generierte Defektbeispiele sind äußerst hilfreich, um ein Defekterkennungsmodell für Fälle zu trainieren oder zu verfeinern, in denen nur eine kleine Menge an ursprünglichen Defektbeispielen oder Inhaltsmerkmalen verfügbar ist.

Die untersuchten Methoden, die eine Feinabstimmung von Grundmodellen mittels eines Multi-Bild-Ansatzes sowie eine Fehlererweiterung in höchster Qualität beinhalten, stellen eine äußerst effiziente Lösung für die Fehlererkennung dar, insbesondere bei kleinen Datensätzen.
